Обзор характеристик семейства C166
Общие характеристики
Семейство
16-разрядных микроконтроллеров Infineon
(бывший Siemens Semiconductors)
C166 содержит кристаллы с
различным уровнем периферии и
производительности,
удовлетворяющие требованиям
широкого спектра специфических
приложений. Все члены семейства С161,
С163, С164-CI, С165, 80С166, и C167 основываются
на одной и той же базовой
архитектуре и поддерживают единую
систему команд (за исключением
расширений для новых членов
семейства). Это позволяет
безболезненно переходить на
следующий уровень
производительности при реализации
более сложного проекта.
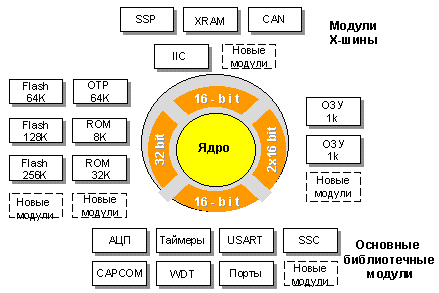
Микроконтроллеры
(МК) строятся по модульному
принципу, предполагающему
разделение на три основных системы:
ядро центрального процессора,
контроллер прерываний и
периферийные модули. Обмен данными
внутри кристалла организован при
помощи четырех внутренних шин:
- 32-разрядная
шина к внутренней памяти
программ, обеспечивает
считывание двухсловных команд
из встроенного ПЗУ за один
цикл;
- две
16-разрядные шины к встроенному
двухпортовому регистровому
ОЗУ, что позволяет
одновременно производить
запись и чтение данных;
- 16-разрядная
шина для обмена с
периферийными модулями;
- дополнительная
16-разрядная X-шина, являющаяся
внутренним продолжением
внешней системной шины, служит
для подключения
дополнительной памяти и новых
периферийных модулей.
Эффективное
программирование МК С166
достигается благодаря мощной
системе команд, поддерживающей
вычисления над 8-, 16- и 32-разрядными
операндами, операции умножения и
деления (MUL, DIV), контроль границ
стека, управление периферией через
регистры специальных функций Special
Function Register (SFR). Следует также
отметить высокую пропускную
способность, мощную систему
адресации и поддержку
программирования на языке высокого
уровня. При тактовой частоте
процессора 16, 20 и 25 МГц цикл
выполнения команды составляет 125,100
и 80нс соответственно.
Команды С166
можно разделить на следующие
основные группы:
- Преобразования
данных: арифметические и
логические команды, операции
быстрого умножения/деления
(0.5/1.0 мкс @ 20МГц), операции
сдвигов на 1...15 разрядов за 100
нс, операции с битами во
встроенном ОЗУ и регистрах SFR.
- Пересылки
данных: команды MOV со всеми
видами адресации,
преобразование байта в слово,
операции с системным стеком
(PUSH, POP) с проверкой на
переполнение и стеком
пользователя (MOV с
автоинкрементом и
автодекрементом).
- Управления
программой: команды
перехода и вызова и условные
переходы по 16 различным
условиям (при выполнении
условия для перехода требуется
только один дополнительный
цикл), программные и аппаратные
ловушки (Traps), быстрые
контекстные переключения за 100
нс.
- Специальные
команды: сокращения
энергопотребления и
системного управления,
непрерываемые
последовательности команд,
специальные приемы адресации.
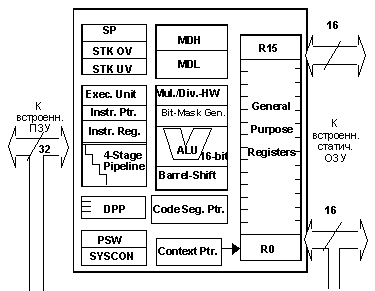
Регистры общего назначения
- Традиционная
CISC-архитектура имеет
один или несколько специальных
регистров, используемых для
арифметических и логических
операций. Например, в
архитектуре 8051 - это один
аккумулятор и 8 регистров
общего назначения для хранения
локальных переменных и
промежуточных результатов
вычислений. Регистры
используются также для доступа
к ячейкам памяти при косвенной
или индексной адресации. В
традиционной CISC-архитектуре
много времени уходит на
перемещение данных из
медленной памяти в область
активных регистров.
- Архитектура RISC
отличается значительно
большим числом регистров
общего назначения или General Purpose
Registers (GPR), которые могут
использоваться для локальных
переменных, параметров и
промежуточных результатов.
Банк GPR в C166 содержит до
шестнадцати 16-разрядных
регистров общего назначения,
каждый из которых может
использоваться как
аккумулятор, указатель при
косвенной адресации или для
хранения индекса. Регистровый
банк включает до 8 регистров с
пословной адресацией и 8
регистров с возможностью
адресации младшего и старшего
байта, все GPR адресуемы побитно.
При столь большом числе
регистров становится
возможным держать все или
почти все локальные и
промежуточные переменные в GPR,
что сокращает частоту
обращений к внешней памяти и
существенно повышает скорость.
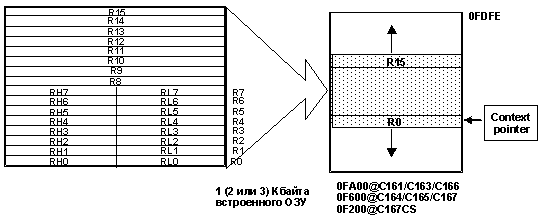
- Следующим
существенным преимуществом
является то, что любой
регистровый банк произвольно
размещается во встроенном ОЗУ.
Расположение активного
регистрового банка определяет
Context Pointer (CP), который содержит
текущий абсолютный базовый
адрес активного банка и
указывает на регистр R0.
Адресация 16 регистров внутри
банка осуществляется с помощью
4-разрядного кода. Для выбора
другого регистрового банка
следует переключить
содержимое CP. Перемещаемость
активного регистрового банка в
пределах встроенного ОЗУ
существенно упрощает
многозадачное управление.
- Хорошим
примером использования CP
является обработка прерывания
при работающей фоновой задаче.
При обработке прерывания, чем
скорее записываются все GPR в
стек, тем лучше. Чтобы на время
обработки переключиться на
новый регистровый банк, CP
текущего регистрового банка
записывается в стек и
переключается на новое
значение. Это приводит к
полному переключению
контекста за один машинный
цикл, но не распространяется на
случай рекурсии.
Гибридный
метод, допускающий вход/выход
в/из прерывания, использует
указатель стека для
динамического вычисления
нового CP. Здесь при входе в
прерывание требуемое число
регистров вычитается из
текущего значения SP и
результат размещается в CP,
старое значение CP заносится в
стек. Новый регистровый банк
размещается сверху старого
стека, содержащего старое
значение CP, и далее сразу же
следует новый стек. При выходе
из прерывания, регистровый
банк восстанавливается при
выполнении команды выборки POP
старого значения CP из стека.
Далее значение SP увеличивается
на размер регистрового банка.
- Еще одним
преимуществом архитектуры RISC
является перекрытие
регистровых банков при вызове
новой процедуры, когда часть
нового регистрового банка,
определяемого CP, соответствует
банку, на который указывает
старый CP:
R3' ; Регистры подпрограммы
R2' ;
R7 R1' ; Общий регистр, R7 == R1'
CP' R6 R0' ; Общий регистр, R6 == R0'
R5 ; Регистры вызывающей программы
R4 ;
R3 ;
R2 ;
R1 ;
CP R0 ;
;============================================================
MODULE 1
;*** Назначение GPR на локальные переменные в вызывающей программе ***
x_var LIT 'R0' ; Локальная переменная
y_var LIT 'R1' ; Локальная переменная
parm1 LIT 'R6' ; Передаваемый параметр 1
parm2 LIT 'R7' ; Передаваемый параметр 2
result LIT 'R6' ; Возвращаемое значение
;============================================================
MODULE 2
;*** Назначение GPR на локальные переменные в подпрограмме ***
a_var LIT 'R2' ; Локальная переменная
b_var LIT 'R3' ; Локальная переменная
input1 LIT 'R0' ; Получаемый параметр 1
input2 LIT 'R1' ; Получаемый параметр 2
ret1 LIT 'R0' ; Окончательный результат R0 |
Таким образом,
тщательная организация данных в
общей области позволяет избежать
загрузки и выгрузки параметров
для передачи в подпрограмму и из
подпрограммы. Местоположение
передаваемых данных должно быть
четко оговорено. Этот прием может
быть реализован как для
абсолютного указателя на
регистровый банк, так и для
относительного режима через
стек. Следует заметить, что
ограниченное количество методов
адресации при выполнении команд
MUL и DIV может привести к
определенным неудобствам при
использовании перекрытия
регистровых банков, поскольку
большинство задействованных в
этих случаях операндов должно
находиться в регистрах.
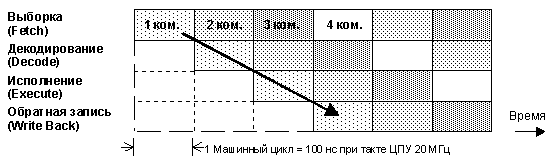
4-х ступенчатый конвейер команд
- Для
увеличения скорости
выполнения команд контроллеры
семейства С166 содержат 4-х
ступенчатый конвейер команд.
За один машинный цикл C166 на
различных ступенях конвейера
выполняет одновременно до 4
команд. Это означает, что
обработка каждой команды по
времени длится четыре машинных
цикла, хотя выполнение команды
происходит в течение одного
цикла. Таким образом,
конвейеризация имеет
существенные преимущества для
ускорения выполнения
последовательности команд при
достаточной пропускной
способности шины. Время
исполнения большинства команд
составляет 100 нс при тактовой
частоте 20МГц.
- Оптимизированная
обработка команд перехода и
вызова (Branch Instruction).
В то время
как при выполнении обычных
команд конвейер не вызывают
проблем, команды перехода и
вызова требуют выполнения
специальных мероприятий. Ко
времени достижения командой
перехода или вызова фазы Execute
следующая по адресу перехода
команда только начинает
исполнение фазы Fetch.
Следовательно, команда,
проходящая в конвейере на фазе Decode
сразу вслед за командой
перехода, должна
игнорироваться. В данном
случае вместо полного очищения
конвейера используется
переход с задержкой ("delayed
branch").
Ситуация с условным переходом
более сложная, т.к. неясно,
будет ли следующая команда
соответствовать результату
проверки условия или нет.
Поэтому при выполнении условия
перехода вставляется холостая
команда на фазе Decode и
требуется дополнительный
машинный цикл. Для ситуаций без
перехода холостая команда не
вставляется и один машинный
цикл экономится. Таким образом,
для команд Jump, Cond. Jump, Call, Return,...
обычно требуется только один
дополнительный машинный цикл
для выборки команды из новой
области памяти.
- Обработка
меток (Loop Control)
Обычная
задача в управляющих
приложениях - просмотр таблиц,
который состоит в повторном
переходе по одному и тому же
фиксированному адресу. Если в
данном случае не предпринять
специальных шагов, то при
обработке каждой метки
возникает бесполезный
машинный цикл. Поэтому здесь
осуществлен механизм
кэширования (Jump Cache). При
первичной обработке метки
вставляется пустая команда и,
как и раньше вхолостую
тратится один машинный цикл.
Однако адрес таблицы
запоминается в кэш-памяти и при
дальнейшем прохождении через
метку адрес извлекается из кэш
и вставляется непосредственно
в фазу Decode. Таким образом, в
данном случае переход
осуществляется за один
машинный цикл.
- Краевые
эффекты конвейера
В фазах Fetch
и Decode может
одновременно осуществляться
запрос шины, если на
завершающей фазе текущей
команды осуществляется чтение.
Предупреждение конфликтов
осуществляет контроллер
внешней шины External Bus Controller,
управляя приоритетами записи,
выборки и чтения.
Следует упомянуть также о
краевых эффектах конвейера,
которые могут возникнуть на
фазе Write Back
при использовании адреса, уже
измененного на фазе Fetch.
Хотя специальное аппаратное
устройство искусственно
передвигает вперед операнды
чтения и записи, необходимо
постоянно об этом помнить.
Команды умножения и деления
занимают 5 и 10 машинных циклов
соответственно и имеют сложный
операционный код. Поскольку
эти команды длятся больше
одного цикла, в конвейер на
стадии Decode вставляются
холостые команды.
Сравнение С166 с микроконтроллерами других архитектур
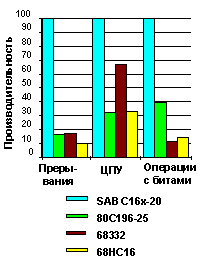
Сравнение
микроконтроллеров является
сложной задачей. Обычно каждый
производитель кристалла
предлагает Benchmark-тесты,
показывающие, что его
микроконтроллер самый лучший. В то
же время сравнительные
характеристики на диаграмме,
опубликованные фирмой Infineon,
полностью совпадают с данными фирм,
поддерживающих кристаллы
нескольких производителей.
В таблице
приведено сравнение CISC-ядра
196 и RISC-ядра С166,
которое проводилось исходя из
числа машинных циклов выполнения
команды. При сопоставлении простых
команд видно, что CISC-архитектура
требует примерно вдвое больше
циклов, чем RISC-архитектура.
Для команд PUSH и POP CISC-архитектура
существенно медленнее и
коэффициент значительно больше чем
4. Если же говорить в целом о готовой
программе, то преимущества RISC
приводят к сокращению времени
выполнения более чем на 50%.
Команды 80C196 Циклы 80C166 Циклы Фактор
--------------------------------------------------------------------------
Move word direct LD x,y 4 MOV Rw,Rw 2 2
Move word indirect LD x,[y] 5 MOV Rw,[Rw] 2 3
Move word indexed LD x,z[y] 7 MOV Rw,[Rw+#d16] 4 3
Add words direct ADD x,y 4 ADD Rw,Rw 2 2
Add words indirect ADD x,[y] 5 ADD Rw,[Rw] 2 3
Add words indexed ADD x,x[y] 7 ADD Rw,[RW+#d16] 4 3
Multiply words direct MUL x,y 16 MUL Rw,Rw 10 6
Divide words direct DIV x,y 26 DIV Rw 20 6
16 bit uncond.jump LJMP #16 7 JMPA cc_UC,#d16 4 3
Shift Left 16 places SHL x,#16 22 SHL Rw,Rw 4 18
Software interrupt TRAP 16 TRAP #n 4 12
Return from subroutine RET 11 RET 2 9
Direct data on stack PUSH x 6 PUSH Rw 2 4
--------------------------------------------------------------------------
Число команд 85 55 |
Еще одним важным
параметром для управляющих
приложений является время
контекстного переключения. Данное
сравнение производилось для
операционной системы реального
времени RTOS CMX при выполнении для
различных микроконтроллеров
следующих условий:
- сохранение
контекста текущей задачи при
поступлении на исполнение
задачи с наивысшим
приоритетом,
- время
переключения не зависят от
особенностей компилятора,
- использованы
сопоставимые модели памяти для
каждого микроконтроллера - без
страничной организации и без
состояний ожидания.
Полученный в
результате фактор скорости
рассчитывался исходя из того, что
все кристаллы работают на
одинаковой приведенной внутренней
тактовой частоте 20 МГц: 80C166 – 1,0;
68332 - 2,26; 68HC16 – 3,10; 80196
– 3,38. Это означает, что
микроконтроллер 80С166 более чем в 2
раза эффективнее справляется с
управляющими приложениями,
требующими постоянного
переключения задач.

|